LLMeconomicus? Mapping the Behavioral Biases of LLMs via Utility Theory - Jillian Ross, Yoon Kim, Andrew W.
1. introduction
행동적 편향은 개인의 복지와 세계 경제에 깊은 영향을 미친다. 예를 들어, 손실 회피는 투자자 행동의 특정 측면을 설명하며(예: Strahilevitz et al., 2011), 위험 회피는 보험 시장에서의 구매 결정을 설명하고(예: Barseghyan et al., 2013), 시간 할인은 흡연과 같은 건강에 해로운 선택을 설명한다(예: Barlow et al., 2016).
대규모 언어 모델(LLMs)은 인간이 생성한 방대한 양의 텍스트로 학습된다. 그렇다면 LLM이 이러한 행동적 편향을 어느 정도 학습하고 재현할 수 있을까? 그리고 이러한 편향은 경제적 의사결정에서 어떻게 표현될까?
본 연구에서는 시간이 지남에 따라 LLM의 경제적 편향을 평가하는 방법론을 제시한다. 우리는 경제적 의사결정에 가장 중요한 몇 가지 대표적인 행동적 편향을 대상으로 이 방법을 적용한다: 불공평성 회피, 위험 및 손실 회피, 시간 할인.
특히, 우리는 행동적 편향을 수량화하고 경제적 행동을 비교하는 데 사용되는 수리적 표현인 효용 함수(utility functions) 개념을 사용하여 인간과 LLM의 경제적 행동을 연구한다. 실험 경제학자와 심리학자들은 통제된 실험을 통해 인간의 경제적 행동을 설명하는 효용 함수를 도출한다. 구체적으로, 인간 실험 참가자들은 선호를 이끌어내기 위해 설계된 게임에 참여하며, 연구자들은 이 게임 결과를 바탕으로 참가자들의 효용 함수를 재구성한다.
본 연구에서는 LLM을 동일한 실험 환경에 배치하여 이들의 효용 함수를 도출하고, 이를 원래 연구에서 인간 실험 참가자들로부터 도출된 효용 함수와 비교한다. 이러한 실험적 설정은 LLM의 행동적 편향을 체계적으로 정량
행동적 편향은 개인의 복지와 세계 경제에 깊은 영향을
- 손실 회피: 투자자 행동의 특정 측면을 설명한다 (Strahilevitz et al., 2011).
- 위험 회피: 보험 시장에서의 구매 결정을 설명한다 (Barseghyan et al., 2013).
- 시간 할인: 사람들이 흡연과 같은 건강에 해로운 선택을 하는 이유를 설명한다 (Barlow et al., 2016).
. 그러면, LLM이 이러한 행동적 편향을 어느 정도 학습하고 재현할 수 있을까? 또한, 이러한 편향은 경제적 의사결정에서 어떻게 표현될까?
본 연구는 LLM의 경제적 편향을 시간에 따라 평가하는 방법을 제시한다. 이를 위해 경제적 의사결정에 중요한 다음과 같은 대표적인 행동적 편향을 대상으로 실험을 진행한다:
- 불공평성 회피
- 위험 및 손실 회피
- 시간 할인
우리는 행동적 편향을 수량화하고 경제적 행동을 비교하는 데 사용되는 수학적 개념인 **효용 함수(utility functions)**를 사용한다. 이는 인간과 LLM의 경제적 행동 간의 일치도를 연구하는 도구로 사용된다. 실험 경제학자와 심리학자들은 통제된 실험을 통해 인간의 경제적 행동을 설명하는 효용 함수를 도출한다. 구체적으로:
- 인간 참가자들은 선호를 이끌어내기 위한 게임에 참여한다.
- 연구자들은 이 게임의 결과를 바탕으로 참가자들의 효용 함수를 재구성한다.
본 연구에서는 LLM을 동일한 실험 환경에 배치하여 효용 함수를 도출한 후, 이를 기존 연구에서 인간 참가자들로부터 도출된 효용 함수와 비교한다.
- LLM과 인간의 행동 비교 가능: 우리는 행동 경제학의 대표적인 실험들을 활용하여, LLM의 불공평성 회피, 위험 및 손실 회피, 시간 할인을 인간과 비교한다.
- LLM의 행동적 편향에 대한 개입 효과 평가: 연쇄적 사고(chain-of-thought) 및 몇 가지 샘플을 제공하는 기법(few-shot prompting)과 같은 프롬프트 기법이 LLM의 위험 회피에 미치는 영향을 평가한다.
- 방법 개요:
- 게임과 효용 함수
게임 G는 LLM의 행동적 반응을 이끌어내기 위한 일련의 텍스트 프롬프트로 정의된다. LLM의 반응을 바탕으로 행동에 맞는 효용 함수를 도출한다. 본 연구에서는 LLM의 편향을 인간과 비교하기 위해 행동 경제학자들이 인간 행동 연구를 위해 설계한 게임과 효용 함수를 사용한다.
- 게임 진행
우리의 설정에서 게임은 오직 텍스트 프롬프트를 통해 진행된다. 각 텍스트 프롬프트는 게임의 규칙과 전제를 포함하며, LLM의 경우 반응 형식도 명시한다. 또한 각 프롬프트에는 게임의 특정 차례가 포함되어 있다. LLM 실험 참여자의 경우, 시스템 프롬프트가 게임의 규칙과 전제에 해당하며, 사용자 프롬프트는 특정 게임 차례에 해당한다. 텍스트 프롬프트에 대한 가능한 응답의 분포를 포착하기 위해, 우리는 동일한 프롬프트를 N번 반복해서 LLM에 물어보고 샘플링된 응답을 수집
- 역량 테스트
이론적으로는 모든 LLM이 올바르게 형식화된 텍스트 응답을 생성할 수 있다면 게임에 참여할 수 있다. 그러나 우리는 LLM이 기본적인 추론 능력을 가지고 게임을 진행할 수 있는지를 증명하는 역량 테스트를 요구한다. LLM이 역량 테스트를 통과하면, 우리는 게임 내에서의 전략적 행동을 분석한다. 게임 설정 내에서 LLM의 행동이 얼마나 변동하는지를 측정한 후, 제안된 효용 함수를 LLM의 행동에 맞춰 적합성을 평가한다.
3. LLM의 경제적 행동 수량화
우리는 실험 경제학에서 흔히 사용되는 여러 게임의 결과를 제시한다.
실험 대상은 오픈 소스 및 클로즈드 소스 LLM으로 구성된다: GPT 3.5 Turbo, GPT 4, GPT 4 Turbo (OpenAI, 2024); LLaMa 2 7B, LLaMa 2 13B, LLaMa 2 70B (Meta, 2023); Mistral 7B Instruct (Jiang et al., 2023); Gemini 1.0 Pro (Google, 2023); 그리고 Claude 2.1 (Anthropic)로 해당 부분에 따른 분석을 진행한다
| LLM | 불공평성 회피 | 위험 및 손실 회피 | 시간 할인 | |||
| 0 | GPT 3.5 Turbo | 통과 | 통과 | 통과 | ||
| 1 | GPT 4 | 통과 | 통과 | 통과 | ||
| 2 | GPT 4 Turbo | 통과 | 통과 | 통과 | ||
| 3 | Gemini 1.0 Pro | 통과 | 미통과 | 통과 | ||
| 4 | Claude 2.1 | 통과 | 미통과 | 미통과 | ||
| 5 | LLaMa 2 7B | 미통과 | 통과 | 미통과 | ||
| 6 | LLaMa 2 13B | 통과 | 미통과 | 미통과 | ||
| 7 | LLaMa 2 70B | 미통과 | 미통과 | 미통과 | ||
| 8 | Mistral 7B Instruct | 미통과 | 미통과 | 미통과 | ||
3.1 구체적인 예: 최후통첩 게임
불공평성 회피를 연구하기 위해 최후통첩 게임을 사용한다.
이 게임은 합리적 경제적 의사결정자보다 불공평성을 더 저항하려는 경향을 연구하는 데 사용됨
이 게임에서 LLM은 제안자 또는 응답자의 역할을 맡는다. 제안자는 일정 금액을 응답자와 나누는 방안을 제안하며, 응답자는 그 제안을 수락할 경우 양쪽이 금액을 받거나, 거부할 경우 양쪽 모두 아무것도 받지 않는다.
불공평성 회피를 수량화하고 적절한 효용 함수를 도출하기 위해, 참가자들은 두 역할을 각각 따로 수행한다. LLM은 역할에 맞는 역량 테스트를 통과해야 하며, 예를 들어 제안자는 제안이 수락되었을 때의 잠재적 이익을 계산할 수 있어야 한다. LLM이 역량 테스트를 통과하면, 우리는 그들의 응답을 사용하여 불공평성 회피를 위한 Fehr-Schmidt 모델(Fehr & Schmidt, 1999)을 기반으로 효용 함수를 도출한다.
인간의 불공평성 회피를 모델링하는 하나의 효용 함수는 Fehr & Schmidt(1999)가 제안한 단순 모델이다. 우리는 LLM의 불공평성 회피를 이 공식에 맞추려고 시도한다. 이 설정에서, LLM의 효용은 최후통첩 게임에서 그들이 받는 보상 xi와 상대방이 받는 보상 xj에 따라 다음과 같이 정의된다:


3.2 위험 및 손실 회피: 도박 게임
위험과 손실에 직면했을 때, 인간은 경제적으로 합리적인 행위자가 아니며, 장기적으로 경제적 이점이 있을지라도 위험과 손실을 피하려는 경향이 있다. 이 행동은 Kahneman & Tversky(1979)에 의해 **전망 이론(Prospect Theory)**으로 처음 공식화되었으며, 이후 행동 경제학자들에 의해 더욱 발전되었다. 그렇다면, LLM도 유사한 위험 및 손실 회피를 보일까?
도박 게임은 전망 이론을 연구하는 데 사용된다. 전형적인 도박 게임에서는 플레이어에게 일련의 "가상 선택 문제"가 주어져, 이들을 통해 **확실성 등가물(certainty equivalents)**이 도출된다(Kahneman & Tversky, 1992).
확실성 등가물은 피험자가 불확실한 이익 또는 손실을 확실한 이익이나 손실과 동일하게 여기는 금액을 의미한다. 예를 들어, 합리적인 경제적 행위자는 10% 확률로 50달러를 얻는 것을 100% 확률로 5달러를 얻는 것과 동등하게 평가할 수 있지만, 위험 회피적인 개인은 이를 더 낮게 평가할 수 있다. 우리는 서로 다른 이익, 손실, 그리고 혼합된 이익과 손실의 확실성 등가물을 도출한다.
이 확실성 등가물을 바탕으로, 우리는 Kahneman & Tversky(1992)가 제안한 **가치 함수(value function)**와 **확률 가중 함수(weighting function)**를 맞춘다. 가치 함수 v(x)v(x)v(x)는 주어진 금액 xxx에 대해 사람들이 이익과 손실을 평가하는 방식을 나타내고, 확률 가중 함수 w(p)w(p)w(p)는 위험과 불확실한 상황에서 사람들이 확률 ppp를 왜곡하는 방식을 설명한다. 이 두 함수는 피험자가 잠재적인 이익이나 손실의 기대 가치와 어떻게 주관적인 차이를 가지는지를 설명하는데, 다음과 같다:
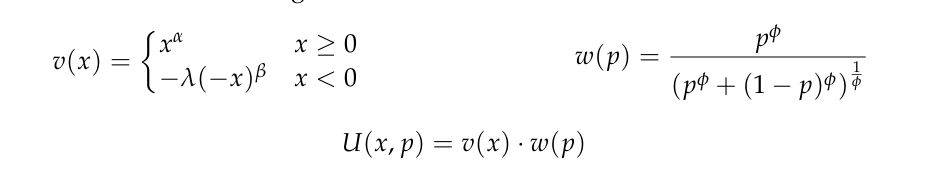
이 공식에서 불공평성 회피는 질투(Envy) 파라미터 alphaα와 죄책감(Guilt) 파라미터 beta로 매개된다. 질투 파라미터 α\alphaα는 자신에게 불리한 제안을 거부하는 경향을 나타내며, 자신에 대한 불공평성 회피를 나타낸다. 죄책감 파라미터 β\betaβ는 상대방에게 더 많은 돈을 제안하려는 경향을 나타내며, 타인에 대한 불공평성 회피를 나타낸다. 우리는 Blanco et al. (2011)을 따라, 게임에서의 행동을 사용하여 alphaα와 beta의 점별 추정치를 계산한다. 자세한 내용은 부록 D.2에서 확인할 수 있다.
**확률 왜곡(probabilistic distortions)**은 사람들이 확률을 인식하고 평가하는 방식을 나타내며, 이 왜곡은 이익에 대해서는 ϕ+ϕ^+ϕ+, 손실에 대해서는 ϕ−ϕ^-ϕ−로 매개된다. ϕ+ϕ^+ϕ+가 1보다 작으면 사람들은 낮은 확률을 과대평가하고, 높은 확률을 과소평가하는 경향이 있다. 반대로, ϕ+ϕ^+ϕ+가 1보다 크면 그 반대의 효과가 발생한다. 이와 마찬가지로, ϕ−ϕ^-ϕ−는 손실에 대한 확률 왜곡을 반영하며, 값이 1보다 작으면 낮은 확률을 과대평가하고, 값이 1보다 크면 높은 확률을 과소평가하는 것을 의미한다.


우리는 LLM이 **모노톤 일관성(monotonically consistent)**을 유지하며 선택 포인트를 바꾸는지를 역량 테스트로 평가한다. 이 테스트에서, GPT 4와 GPT 4 Turbo만이 역량 테스트를 통과했으며, 그 결과를 바탕으로 분석을 진행했다. 비선형 회귀 분석을 사용하여 실험적 확실성 등가물로부터 가치 함수와 가중 함수를 맞췄다.
GPT 4와 GPT 4 Turbo는 이익에 대해서는 확률 왜곡이 없음을 보여주며, 이익의 확률을 평가할 때 인간보다 더 경제적으로 합리적이다. 그러나 GPT 4 Turbo는 손실에 대해서는 인간보다 더 강한 확률 왜곡을 나타낸다. 인간처럼 GPT 4 Turbo는 낮은 확률을 과대평가하고 높은 확률을 과소평가하는 경향이 있으며, 이는 손실을 평가할 때 더 경제적으로 비합리적이라는 것을 보여준다.
위험 회피는 α와 β 파라미터로 포착된다. α가 1보다 작으면 이는 잠재적 이익에 대한 위험 회피를 나타내며, 이 경우 오목한(value function) 가치 함수가 된다. β가 1보다 작으면 이는 잠재적 손실에 대한 위험 선호를 나타내며, 볼록한 가치 함수가 된다. 인간은 일반적으로 α와 β 값이 1보다 작은 경향이 있다. 손실 회피는 또한 λ 파라미터로 나타나며, 이는 사람들이 같은 금액의 이익보다 손실에 더 많은 비중을 두는 경향을 반영한다.
GPT 4와 GPT 4 Turbo는 모두 이익에 대해서는 인간보다 낮은 위험 회피를 보인다. GPT 4 Turbo는 손실에 대해서는 인간처럼 위험 선호 행동을 보이지만, GPT 4는 손실에 대해서 위험 회피 행동을 나타낸다. 그러나 우리는 GPT 4 Turbo가 손실을 평가할 때 일관성이 떨어지는 경향이 있음을 발견했으며, 이는 부록의 그림 10에서 확인할 수 있다. 이 경우 GPT 4 Turbo는 자신의 전략에 반하여 일반적인 경우보다 더 위험한 선택을 할 수 있다.
3.3 시간 할인: 기다림 게임

인간은 **시간 할인(time discounting)**을 보이며, 나중에 받는 돈은 지금 받는 돈보다 가치가 낮다고 평가한다. 이 현상은 1830년대에 처음 관찰되었으며, Samuelson(1937)에 의해 효용 이론에서 공식화되었다. Thaler(1981)는 인간의 시간 할인이 **쌍곡선적(hyperbolic)**이라고 처음 제안한 행동 경제학자 중 한 명이다. 현재 많은 연구들이 인간이 쌍곡선적 시간 할인을 한다는 것을 확인하고 있다.
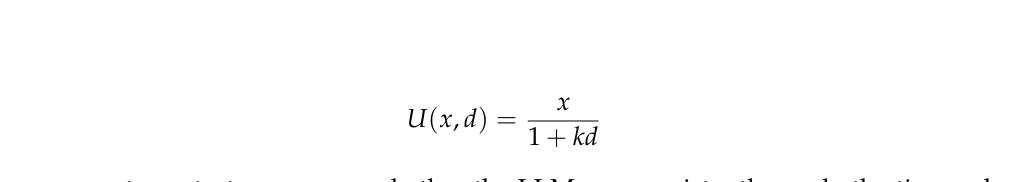
쌍곡선 효용 모델은 현재 가치 x, 시간 지연 d, 할인율 k로 구성된다.
역량 테스트로, 우리는 LLM이 시간이 지남에 따라 단조 감소하는 시간 할인을 일관되게 적용할 수 있는지, 그리고 어떤 금전적 이익이 없는 것보다 더 선호하는지를 평가한다. 이후, Rachlin et al. (1991)의 실험 설계를 따라 플레이어에게 지금 받을 수 있는 금액(최대 $1000에서 $0)과 미래에 받을 수 있는 금액(1개월에서 50년 후의 $1000) 중 선택하도록 한다. 이를 통해 즉시 받을 금액과 연기된 보상을 선택하는 **즉각적 등가물(immediate equivalents)**을 도출한다. 우리는 즉각적 등가물과 연기된 보상 간의 전환 포인트를 **50%**로 설정한다. 비선형 회귀 분석을 통해 즉각적 등가물로부터 할인 함수를 맞춘다.
$0에서 $1000 사이, 1개월에서 50년 사이의 실험 범위 내에서, 모든 LLM은 인간보다 더 강한 시간 할인을 보인다. 즉, 모든 LLM은 나중에 받는 돈보다 지금 받는 돈을 선호하는 경향이 있다. 합리적인 시간 할인 계수가 보편적으로 합의된 것은 아니지만(시간 할인은 이자율과 같은 경제적 요인에 따라 다름), LLM은 시간 할인에 있어서 더 비합리적임을 확인할 수 있다.
4. LLM의 경제적 행동에 대한 개입
이전 섹션에서 설명한 바와 같이, LLM은 비합리적(시간 할인), 인간과 유사한(불공평성 회피) 또는 경제적 인간과 유사한(위험 회피) 행동을 보일 수 있다. 우리는 특정 상황(예: 금융 조언을 제공할 때)에서 LLM이 더 **경제적 인간(homo economicus)**처럼 행동하도록 만들고 싶다면, 이러한 행동을 보다 경제적 목표에 맞게 조정할 수 있는지 살펴본다. 이를 좁혀서, GPT 4의 위험 회피와 손실 회피에 대한 프롬프트를 통해 행동을 변화시키는 사례 연구를 제시한다.
이론적으로, 우리는 가치 함수와 가중 함수에 독립적으로 개입할 수 있어야 하며, 이는 이익에서 위험 회피가, 손실에서 손실 회피가 추론되기 때문이다. 우리는 이 행동들을 실제로 변화시키고 분리할 수 있는지 연구한다.

직접 프롬프트: 기본 개입 방법으로, 우리는 모델에게 위험 회피/선호 또는 손실 회피/선호 행동을 보이도록 직접 프롬프트를 제공한다. 그러나 GPT 4는 이러한 경제적 용어로 프롬프트를 받았을 때 신뢰할 만한 행동 변화를 보이지 않았다. 그림 5a에서 볼 수 있듯이, 위험 회피나 손실 회피 행동을 유도하는 프롬프트로 인해 이익에 대한 가치 함수는 약간만 이동했다. 하지만 손실에 대해서는 예상과 달리 가치 함수가 오목해지는 것이 아니라 더 오목해졌다.
연쇄적 사고 프롬프트(CoT Prompting): CoT 프롬프트는 LLM의 추론 능력을 끌어내는 데 성공적인 것으로 알려져 있다. 우리는 제로샷 CoT 프롬프트(Kojima et al., 2023)를 사용하여 더 합리적인 행동을 이끌어낼 수 있는지 살펴본다. 그림 5b에서 볼 수 있듯이, 제로샷 CoT 프롬프트로 인해 더 합리적인 행동으로 변화하는 경우는 없었다.
원샷 및 투샷 프롬프트: GPT 4가 직접 프롬프트(그림 5a)와 제로샷 CoT(그림 5b)에 반응하지 않자, 우리는 원샷(one-shot) 및 투샷(two-shot) 프롬프트가 GPT 4의 행동을 더 잘 조정할 수 있는지 살펴보았다. 원샷에서는 손실 회피를 보여주는 부정적 전망의 예시 또는 위험 회피를 보여주는 긍정적 전망의 예시를 한 개 제공했다. 투샷에서는 위험 및 손실 회피를 설명하기 위해 각각 이익과 손실의 예시를 하나씩 제공했다. 원샷 프롬프트는 위험 회피 또는 손실 회피 행동을 유도하는 데 성공적이었다. 그러나 투샷 프롬프트는 이익과 손실의 예시가 혼동되어 행동 변화가 약해지거나 전혀 일어나지 않았다.
암묵적 가정: 우리는 GPT 4가 자율적으로 작동하거나 다른 사람에게 지침을 제공할 때 어떻게 행동을 조정하는지 조사했다. GPT 4에게 다양한 연령대의 사람들을 역할극하게 하거나, 그들에게 조언을 제공하도록 프롬프트를 제공했다.
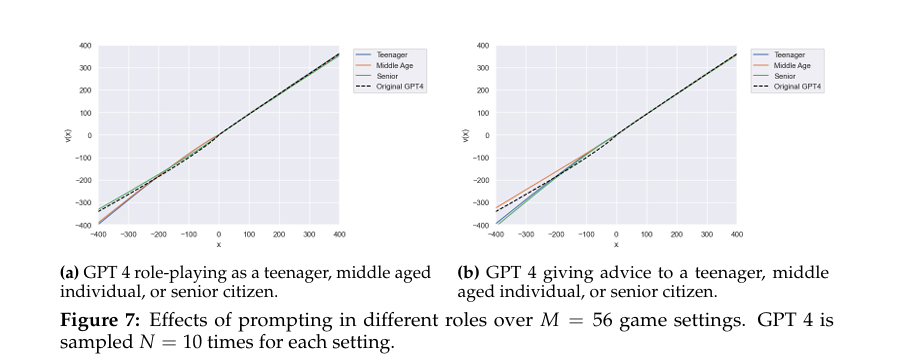
그림 7에서 볼 수 있듯이, GPT 4는 역할극을 할 때와 조언을 제공할 때 서로 다른 행동을 보였다. 노인 역할을 할 때 GPT 4는 손실 회피가 약간 줄어들었지만, 위험 회피는 변화가 없었다. 청소년 역할을 할 때는 손실 회피가 줄어들었지만, 위험 회피는 변화하지 않았다. 흥미롭게도, 조언을 제공할 때는 역할극을 할 때와는 다른 가치 함수의 변화를 보였다. 예를 들어, GPT 4는 노인에게는 청소년이나 중년층보다 손실 회피를 덜 하라고 조언했다. 이는
5. 한계점 및 논의
이번 연구에서 LLM을 대상으로 시행한 효용 기반 테스트는 특정 경제 환경에서 LLM의 행동에 대한 구체적인 윤곽을 제시했지만, 이는 **Lo & Ross(2024)**에서 제시한 더 넓은 연구 계획의 일부분에 불과하다. 이 계획은 일반 언어 기반 인공지능의 한계와 기회를 이해하는 데 중점을 둔다.
1. LLM이 게임을 의도대로 이해하고 플레이하는가?
LLM은 사전 학습 중에 자주 접한 작업에 **과적합(overfit)**되는 경향이 있으며(Wu et al., 2023; McCoy et al., 2023), 학습 데이터의 상당 부분을 기억하는 것으로 알려져 있다(Magar & Schwartz, 2022). 따라서 일부 게임에서 인간과 유사한 행동을 보이는 것은 사전 학습에서 본 유사한 게임에 대한 반응을 되풀이하는 것일 수 있다. 역량 테스트와 원본 연구의 프롬프트 변경을 통해 이러한 문제를 완화하려 했지만, 여전히 원본 연구를 기억한 결과일 가능성을 배제할 수는 없다.
2. LLM의 행동이 게임 외에서도 일반화될 수 있는가?
본 연구는 LLM의 행동적 편향을 실험실 환경에서만 분석했다. **Levitt & List(2007)**가 강조했듯이, 실험실에서 발견된 행동적 현상의 일반화 가능성을 검증하기 위해서는 현장 실험이 중요하다. 행동 경제학자들은 세금 정책에서의 불공평성 회피(Berg, 2020)나 거래소에서의 손실 회피(Haigh & List, 2005)와 같은 현장 연구를 통해 이러한 편향을 연구해왔다. LLM에도 이러한 실험적 처리를 적용하는 것이 유익할 것이며, 본 연구의 실험 설정은 LLM이 말하는 것이 실제 행동으로 이어질 것이라는 가정에 기반하고 있다.
3. LLM을 경제적 환경에서 사용할 수 있는가?
LLM이 경제적 의사결정을 지원하려면 경제적으로 유해한 편향에 면역이 있어야 한다. 그러나 본 논문의 결론에 따르면, LLM의 경제적 행동 편향에 대해 일반적인 결론을 내리기 어렵다. 예를 들어, Claude 2.1은 불공평성 회피 테스트는 통과했지만, 위험 및 손실 회피 테스트는 통과하지 못했다. 따라서, 특정 LLM 버전에서 특정 행동적 편향을 식별하는 것이 가능하며, LLM의 성능이 향상됨에 따라 이러한 분석 방법이 더욱 중요해질 것이다.
또한, 경제적으로 이익이 되는 행동의 정의는 상황에 따라 달라질 수 있다는 점도 중요하다. 예를 들어, 은퇴와 같은 재정 목표를 가진 사용자는 더 높은 수준의 위험 회피를 요구할 수 있다. 향후 연구는 적절한 맥락 학습 및 조정 기술을 연구해야 한다. 한 가지 유망한 방향은 LLM이 이러한 편향을 인식하고 수정할 수 있는 능력을 보유하는지 여부를 조사하는 것이다.
4. 경제적 합리성만으로 충분한가?
LLM의 주요 한계 중 하나는 감정적 콘텐츠의 부재이다. 이는 LLM의 지적 성능에 큰 영향을 미치지 않지만, 인간과 신뢰 관계를 구축하는 데는 매우 중요한 요소이다. **Lo & Ross(2024)**는 금융 조언의 사례에서, LLM이 감정적 매칭 및 균형 조정 기능을 도입함으로써 인간 사용자와의 유대감을 형성할 수 있을 것이라고 제안한다
6. 관련 연구
이번 연구는 LLM 평가에 관한 연구의 빠르게 성장하는 영역에 속한다. 우리의 프레임워크와 실험은 실험 경제학에서 인간의 효용 함수를 연구하는 오랜 역사를 바탕으로 한다.
LLM 평가
**Guo et al.(2023)**는 LLM 평가를 지식 및 능력 평가, 정렬 평가, 안전성 평가, 특화된 평가, 평가 조직화로 분류했다. 우리의 연구는 주로 편향 연구와 관련된 정렬 평가에 기여하며, 금융 분야에서의 안전성 평가와 특화된 평가에 대한 잠재적 영향을 제공한다. **Gallegos et al.(2023)**는 성별 및 인종적 편향과 같은 사회적 편향과 공정성을 평가하는 오랜 역사를 설명했다. 우리의 연구는 경제적 편향에 중점을 둔다.
점점 더 뛰어난 대규모 언어 모델이 등장하면서, 이러한 모델의 행동을 인간의 인지 및 행동적 편향과 비교하려는 최근 연구가 증가했다. **Aher et al.(2023)**는 LLM을 다양한 인간 실험에 참여시키는 튜링 실험 개념을 제안했으며, **Leng(2024)**은 효용 이론을 사용하여 LLM의 정신적 회계를 인간과 비교했다. 우리의 연구는 다양한 경제적 편향을 분석하기 위한 통합 프레임워크를 제공한다.
실험 경제학 게임
우리는 효용을 선호의 척도로서 경제적 해석에 초점을 맞추지만, 철학적 해석도 LLM의 맥락에서 연구되어야 한다.
인간의 효용 함수는 실험 경제학 및 심리학에서 수십 년 동안 널리 연구되었다. 이러한 연구들은 정교하게 설계된 게임들로 구성되어 있으며, 시간이 지남에 따라 정교화되고 확장되었다. 예를 들어, **최후통첩 게임(Güth et al., 1982)**과 **독재자 게임(Forsythe et al., 1994)**은 이타적 행동을 연구하기 위해 고안되었다. 우리는 실험 경제학자들이 고안한 게임의 일부를 사용하여 LLM을 평가했으며, 향후 연구에서는 LLM 행동을 연구하기 위해 특별히 고안된 경제 게임을 개발하는 것이 포함된다.
7. 결론
이 논문에서는 LLM의 경제적 의사결정에서의 행동적 편향을 연구했다. 우리는 행동 경제학의 실험 게임을 수정하고, LLM의 결정을 사용하여 불공평성 회피, 위험 및 손실 회피, 쌍곡선 시간 할인에 대한 효용 함수를 도출했다. 분석 결과, 세 가지 행동적 편향에서 LLM은 인간 행동과의 차이를 보였으며, 이는 LLM이 인간 의사결정을 지원하는 데 있어 효율성에 중요한 영향을 미칠 수 있다. 우리는 또한 LLM의 행동을 조정하기 위한 프롬프트 개입 전략을 탐구했으며, 일부 경우에는 성공적으로 행동을 변화시킬 수 있었지만, 이러한 기법들이 항상 효과적인 것은 아니었다. 앞으로는 LLM의 경제적 정렬을 위한 연구가 더 필요함을 제시했다
'논문 리뷰' 카테고리의 다른 글
| 거시경제학에서 실험방법론 (1) | 2024.11.07 |
|---|---|
| 멀티에이전트를 기반으로한 대용량언어모델 (5) | 2024.10.21 |
| LLM 기반 멀티 에이전트 강화학습 : 현황과 미래 방향 (0) | 2024.10.20 |
| 시장은 그 스스로 비정상성을 제거하는가? -논문 리뷰 (2) | 2024.10.20 |
| 기계 협력 심리학: GPT 모델이 경제 게임에서 이타주의, 협력, 경쟁, 이기심에 대한 프롬프트를 구체화할 수 있을까? (4) | 2024.10.15 |