THE MACHINE PSYCHOLOGY OF COOPERATION: CAN GPT MODELS OPERATIONALISE PROMPTS FOR ALTRUISM, COOPERATION, COMPETITIVENESS, AND SELFISHNESS IN ECONOMIC GAMES?- Steve Phelps1 and Yvan I. Russell 2024.july
서문
2022년 말, OpenAI에서 개발한 챗봇 ChatGPT 버전 3.5가 공개되었고
많은 사용자들은 ChatGPT와 같은 챗봇은 종종 창의력을 발휘하는 듯 보이며 , 참신하고 잘 쓰인 답변을 생성하여 그것이 사람의 응답처럼 그럴듯하게 느껴지게 만듭니다 ChatGPT는 심층 신경망 모델을 활용하여 자연어 처리를 수행
LLM은 입력된 문맥에 따라 가능한 다음 토큰의 확률을 예측한 후, 해당 확률 분포에 따라 임의로 선택됩니다. 이때 "온도(temperature)"라는 매개변수를 사용하여 이 확률 분포를 조정할 수 있으며, 온도가 높으면 더 많은 무작위성이, 온도가 낮으면 결정론적 결과가 나타납니다 결국 온도가 낮으면 출력의 "창의성"을 높이는 데 기여한다고 여길수 있음
반면, 새로운 대규모 모델은 훨씬 더 뛰어난 성능을 보여주며, "제로샷 학습"을 통해 이전 예제 없이도 새로운 답변가능
기존 연구
| 연구자 | ,대상 게임 | ,주요 실험 조건 | 결과 | |
| Brookins & de Backer | DG(독재자 게임) & 1회성 PD(죄수의 딜레마) | 다양한 보상 매개변수에서 시뮬레이션 | GPT 에이전트가 인간보다 공정하고 협력적 | |
| Lore et al. | 4가지 경제 게임(PD 포함) | 문맥 처리(4가지 문맥) 및 높은 온도(0.8) 설정 | GPT-3.5는 문맥에 민감, GPT-4는 게임의 기본 논리에 주목 | |
| Guo | UG(최후통첩 게임) & PD | 사회적 선호 조건(WS) 및 비사회적 선호 조건(NS) | WS 조건에서 UG 및 PD 게임에서 더 높은 협력성을 보임 | |
| Horton | DG(독재자 게임) | Charness와 Rabin의 2002년 연구 기반 '성격 차이' 프롬프트 | GPT-3.5는 '성격 차이'에 따라 자기 이익 중심 선택 | |
2.1 실험 설계
- 기본 구조: 반복된 죄수의 딜레마 실험을 기반으로, LLM 시뮬라크라와 시뮬레이션된 상대방 간의 온라인 상호작용을 진행.
- 게임 구조: 각 참가자는 6라운드 동안 죄수의 딜레마 게임을 플레이하고, 모든 실험은 동일한 조건에서 3번(R=3) 복제됨.
- 보상 구조: 다음과 같은 보상 매트릭스를 사용:
- T=7T = 7, R=5R = 5, P=3P = 3, S=0S = 0
- 이를 통해 T>R>P>ST > R > P > S 및 2R>T+S2R > T + S의 조건을 충족.
- 종속 변수: 참가자의 협력 빈도가 종속 변수로 설정됨. 협력 횟수를 총 라운드 수로 나눈 비율로 계산.
2.2 참가자와 시뮬라크라
- 연구 목표: GPT 모델이 이타적 또는 이기적 동기를 얼마나 잘 구현할 수 있는지 평가.
- 5개의 시뮬라크라 그룹:
- 협력적
- 경쟁적
- 이타적
- 이기적
- 통제군
- 프롬프트 설계: 각 그룹 내에서 협력 또는 비협력적 행동을 유도하는 자연어 설명을 작성. 각 그룹마다 3가지 다른 프롬프트를 사용하여 특정 문구에 의존하지 않도록 설계.

- 프롬프트 다양화: GPT 모델의 민감성을 고려하여, 의미에 영향을 미치지 않는 요소들을 무작위로 변경하여 프롬프트를 다양화함.
- 샘플링: 5개의 그룹에 대해 3개의 프롬프트를 사용하고, 각 프롬프트는 n=30의 속성 조합을 무작위로 샘플링함. 총 450명의 참가자(N=450)가 실험에 참여.
- 분석 목표: 다양한 파트너 조건 및 속성의 랜덤 효과를 통계 모델링으로 분석하여, 각 그룹 간 협력 빈도에 유의미한 차이가 있는지 조사.
2.3 반복 실험
- 독립적인 게임: 인간 피험자와 달리, 각 게임 플레이는 독립적이므로 동일 참가자가 여러 조건에서 반복 측정하더라도 연속적인 영향을 받지 않습니다.
- 설계: 동일 참가자는 각 조건에서 총 4번의 반복 게임을 플레이했으며, 이는 t = 0, 1, 2로 기록되었습니다.
2.4 파트너 조건
- 파트너 조건:
- 무조건적인 배신: 파트너는 항상 배신을 선택.
- 무조건적인 협력: 파트너는 항상 협력을 선택.
- 보복 협력(C): 첫 번째 이동에서 협력하고, 이후 시뮬라크라의 이전 선택에 따라 협력 또는 배신.
- 보복 배신(D): 첫 번째 이동에서 배신하고, 이후 시뮬라크라의 이전 선택에 따라 행동.
- 실험 설계: 각 참가자는 주어진 조건에서 총 12번의 독립적인 게임을 플레이했습니다.
2.5 매개변수와 실험 프로토콜
- API 사용: OpenAI 챗 컴플리션 API를 사용해 실험을 진행. 각 요청당 최대 토큰 수는 500으로 설정.
- 모델 및 온도 설정: 세 가지 모델 버전과 두 가지 온도(0.1과 0.6)에서 실험을 반복해 데이터 수집.
- 참가자 수: 각 모델/온도 조합에서 450명의 참가자를 대상으로 실험. 각 참가자는 72번의 독립적인 게임을 수행하여 총 32,400개의 관측치 확보.
- 실험 절차: 시뮬라크라는 사용자 역할의 프롬프트에 따라 행동하며, 어시스턴트 역할과 교대로 메시지를 주고받으며 게임을 진행.
2.6 데이터 수집 및 분석
- 데이터 추출: 각 라운드에서 시뮬라크라와 시뮬레이션된 파트너 간의 대화 데이터를 수집 및 기록. 정규 표현식을 사용해 선택을 추출.
- 종속 변수: 최종 협력 빈도를 기록. 협력 선택 횟수를 전체 라운드 수로 나누어 계산.
- 분석 도구: 전체 Python 코드는 공개된 저장소에 저장됨.
- 가설:
- 각 그룹의 시뮬라크럼이 어떻게 행동할지를 예측했습니다:
- 이타적 그룹: 무조건 협력자처럼 행동하여, 자신의 이익이 감소하더라도 상대방에게 이익을 주는 방식으로 협력할 것이라 가정.
- 협력적 그룹: 조건부 상호성을 사용하여 첫 번째 게임에서는 협력하고, 이후 반복되는 게임에서는 티포탯(Tit for Tat) 전략을 따를 것이라 예상.
- 경쟁적 그룹: 무조건 배신자처럼 행동하여 상대방의 이익을 최소화하는 방식으로 행동할 것이라 예상.
- 이기적 그룹: 때때로 협력을 통해 상호 협력을 유도한 후, 상대방의 신뢰를 악용하여 배신할 것이라 예상.
- 각 그룹의 시뮬라크럼이 어떻게 행동할지를 예측했습니다:
- 가설:
- 가설들
H1 모든 그룹의 시뮬라크라는 통제군과 다른 협력 빈도를 보일 것이다. 가설 분석: 각 그룹이 통제군과 비교하여 다르게 행동할 것으로 예상됩니다. 협력적, 경쟁적, 이타적, 이기적 그룹 모두 통제군과 차별화된 협력 행동을 보일 가능성이 큽니다. H2 이타적인 프롬프트로 구현된 시뮬라크라는 다른 그룹에 비해 가장 높은 협력 빈도를 보일 것이다. 가설 분석: 이타적인 행동을 유도하는 프롬프트가 협력 빈도를 극대화할 것으로 예상됩니다. 이는 사회적 딜레마에서 이타적 성향이 협력을 촉진하는 중요한 요소라는 점을 뒷받침합니다. H3 협력적인 프롬프트로 구현된 시뮬라크라는 경쟁적, 이기적 프롬프트에 비해 더 높은 협력 빈도를 보일 것이다. 가설 분석: 협력적 태도가 경쟁적, 이기적 태도에 비해 더 많은 협력 행동을 유도할 것으로 보입니다. 이는 프롬프트가 협력적 사고를 형성하는 데 중요한 역할을 한다는 점을 보여줍니다. H4 반복 게임에서 시뮬라크라는 일회성 게임보다 더 높은 협력 빈도를 보일 것이다. 가설 분석: 반복되는 상호작용은 협력을 강화하는 경향이 있습니다. 이는 반복 게임이 미래의 보상을 고려하게 만들기 때문에 협력을 촉진하는 효과가 있음을 시사합니다. H5 GPT-3.5-turbo 모델의 다양한 버전은 다른 조건에서 동일한 협력 빈도를 보일 것이다. 가설 분석: 모델 간의 협력 빈도 차이가 없을 것으로 예상되며, 이는 모델의 일관성을 나타냅니다. 협력 수준은 모델의 버전에 관계없이 유사할 것으로 보입니다. H6 이타적인 프롬프트로 구현된 시뮬라크라는 파트너 조건과 관계없이 높은 협력 수준을 보일 것이다. 가설 분석: 이타적인 프롬프트는 상황에 관계없이 일관된 협력 행동을 유도할 가능성이 큽니다. 이는 이타적 태도가 상황적 요인에 크게 좌우되지 않음을 나타냅니다. H7 이기적인 프롬프트로 구현된 시뮬라크라는 파트너 조건과 관계없이 최소한의 협력 수준을 보일 것이다. 가설 분석: 이기적 프롬프트는 협력을 최소화할 가능성이 높습니다. 이는 이기적 성향이 상호 이익을 고려하지 않음을 보여줍니다. H8 협력적인 프롬프트로 구현된 시뮬라크라는 무조건 협력하거나 협력으로 시작하는 티포탯 파트너와 함께 있을 때 더 높은 협력률을 보일 것이다. 가설 분석: 상대가 협력적으로 행동할 경우, 협력적 프롬프트로 구현된 시뮬라크라가 더 높은 협력 빈도를 보일 것으로 예상됩니다. 상호 협력의 긍정적 강화 효과를 보여줍니다. H9 협력적인 프롬프트로 구현된 시뮬라크라는 무조건 배신하는 파트너에 비해 티포탯 파트너와 함께 있을 때 더 높은 협력률을 보일 것이다. 가설 분석: 상대의 협력적 대응이 협력적 시뮬라크라의 협력 빈도를 증가시킬 가능성이 높습니다. 이는 신뢰와 상호작용이 협력을 촉진하는 요소임을 시사합니다. H10 경쟁적인 프롬프트로 구현된 시뮬라크라는 파트너 조건과 관계없이 낮은 협력 수준을 보일 것이지만, 이기적인 시뮬라크라보다는 더 높은 협력 수준을 보일 것이다. 가설 분석: 경쟁적 시뮬라크라는 낮은 협력 수준을 보이지만, 이기적 시뮬라크라보다는 더 나은 협력 성향을 보일 것으로 예상됩니다. 경쟁은 협력에 어느 정도 기여할 수 있음을 보여줍니다.
3.1 탐색적 데이터 분석
- 협력 빈도 비교: 죄수의 딜레마와 독재자 게임에서 참가자 그룹별 협력 빈도 분석.
- 결과 요약: 반복된 죄수의 딜레마 실험에서 일관되게 높은 협력 빈도를 보였으며, 모델 간 협력 빈도 분포에 차이가 나타남.

3.2 통계 분석 방법론
- 죄수의 딜레마: 협력 여부를 이항 변수로 설정하고, 파트너 조건과 시간에 따른 변동을 고려한 **일반화 선형 혼합 모델(GLMM)**을 사용.
- 독재자 게임: 반응 변수의 분포를 고려해 **누적 연결 혼합 모델(CLMM)**을 사용해 분석.

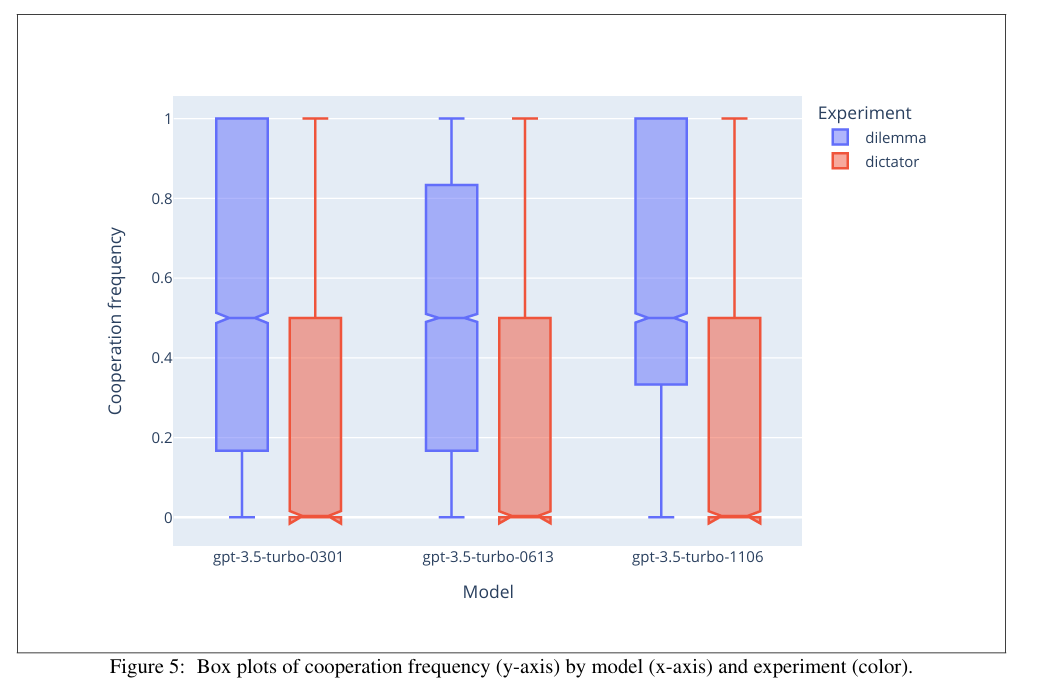

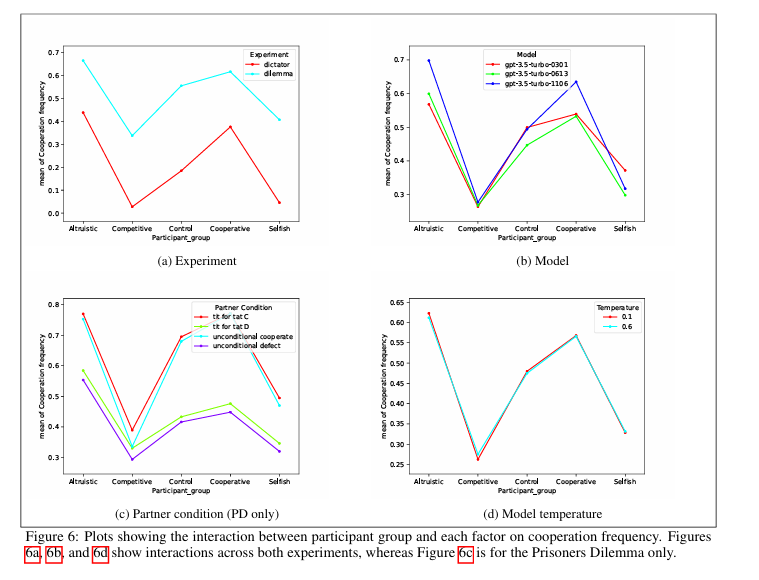
3.2.1 죄수의 딜레마 분석 결과
- 주요 그룹별 결과 요약
- 이기적 그룹(Selfish group):
- H7 가설과의 차이: 초기 가설(H7)은 이기적 그룹이 항상 배신할 것이라고 예측했으나, 초기 버전의 GPT 모델(gpt-3.5-turbo-0613 및 gpt-3.5-turbo-0301)을 사용한 시뮬라크라는 배신자(D 또는 T4T4)보다는 협력자(T4TC 또는 C)와 있을 때 더 협력
- 최신 GPT 모델: gpt-3.5-turbo-1106 모델은 이 가설에 더 부합하는 결과를 보였으며, 파트너 조건에 따른 유의미한 차이가 없음.
- 경쟁적 그룹과의 비교: 모든 GPT 모델은 경쟁적 그룹에 비해 더 높은 협력 확률을 보였음.
- 경쟁적 그룹(Competitive group):
- H10 가설과 일치: gpt-3.5-turbo-0301 및 gpt-3.5-turbo-1106 모델을 사용한 시뮬라크라는 예상대로 파트너 조건에 따라 협력 확률에 유의미한 차이가 없었습니다.
- 협력 확률: 협력 확률은 0.4 이하로 낮았지만, 예상보다 약간 높은 수준을 보였습니다.
- 특이점: gpt-3.5-turbo-0613 모델은 배신자(D)와 협력자(T4TC) 사이에서 협력 확률의 차이가 더 컸음.
- 협력적 그룹(Cooperative group):
- H8 가설 지지: 협력적 그룹의 시뮬라크라는 협력적 파트너(T4TC)와 함께 있을 때 협력 확률이 크게 증가했습니다. 티포탯(Tit-for-Tat) 전략을 따르는 파트너와 있을 때도 무조건 배신자에 비해 더 높은 협력 확률을 보임
- H9 기각: 무조건 배신자(D)와 티포탯 배신자(T4TD) 사이에서 예상보다 더 관대하게 행동했으며, 유의미한 차이를 보이지 않음
- 모든 GPT 모델에서 일관된 결과: 협력적 시뮬라크라는 모든 모델에서 높은 협력 성향을 보임
- 이타적 그룹(Altruistic group):
- H6 부분적 기각: 초기 GPT 모델을 사용한 시뮬라크라는 협력적이지 않은 파트너와 있을 때 협력 확률이 감소
- 최신 GPT 모델: gpt-3.5-turbo-1106 모델을 사용한 시뮬라크라는 협력적이든 비협력적이든 상관없이 높은 협력 확률(≥ 0.75)을 보임.
- 파트너 조건의 효과가 일부 유의미했으나, 초기 모델에 비해 효과 크기가 매우작음.
- 통제 그룹(Control group):
- H1 기각: 모든 모델에서 통제 그룹의 결과는 협력적 그룹과 유사한 패턴을 보였으며, 협력자와 배신자 사이에서 나타난 효과 크기가 협력적 그룹에 비해 약간 작음
- 이기적 그룹(Selfish group):


3.2.3 독재자 게임 분석 결과
- 과산포 문제: 독재자 게임에서는 반응 변수의 분포가 이항/포아송 분포를 따르지 않아 CLMM을 사용.
- CLMM을 사용해 분석을 수행했고, 이는 독재자 게임의 결과에 더 적합한 분석 방법이었음
- 참가자 그룹, 모델, 온도, 상호작용 항 등이 고정 효과로 포함되었으며, t 변수는 제외
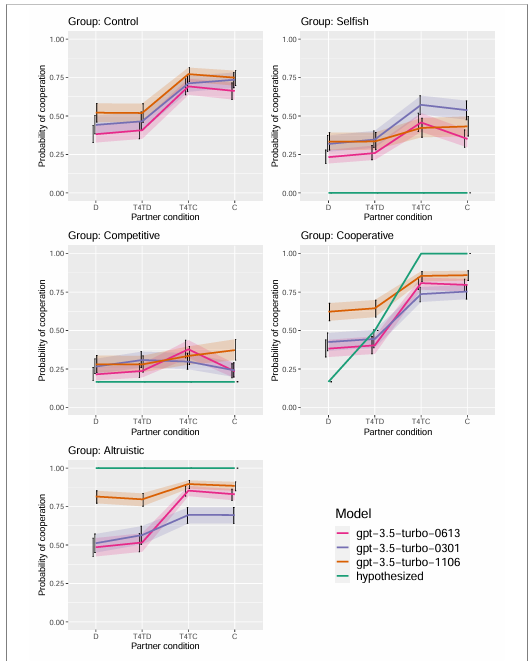

4. 논의
- 실험 결과 요약:
- 독재자 게임(Dictator Game):
- GPT 모델은 협력적인 태도를 일관되게 구현해내었으며, 실험 심리학자의 기대에 부합하는 방식으로 게임을 수행했습니다.
- 다만, 이타적 시뮬라크럼이 협력적 시뮬라크럼에 비해 기부 횟수를 유의미하게 증가시키지 않아 예상과는 다른 결과를 보였습니다.
- 죄수의 딜레마(Prisoner's Dilemma):
- 혼합된 결과를 보였습니다.
- 지지된 가설:
- H3, H4, H8: 협력적 시뮬라크럼은 이기적, 경쟁적 시뮬라크럼보다 더 높은 협력 빈도를 보였으며, 반복 게임에서 협력 빈도가 더 높았고, 티포탯(Tit-for-Tat) 파트너와 있을 때 협력 빈도가 더 높았음
- 부분적으로 지지된 가설:
- H1, H2, H6, H10: 통제군은 협력적 시뮬라크럼과 유사한 행동을 보였고, 이타적 시뮬라크럼은 반복 게임에서 가장 많이 협력했으나, 초기 모델에서는 결함이 있었습니다.
- 기각된 가설:
- H5, H7, H9: 이기적 시뮬라크럼이 반복 게임에서 일부 협력하였으며, 협력적 시뮬라크럼은 티포탯 전략에서 첫 번째 배신자에 대해 더 높은 협력률을 보이지 않았습니다.
- 전체 협력 패턴:
- 협력 빈도는 이타적 ≥ 협력적 > 통제군 > 이기적 ≥ 경쟁적 순
- 협력적 프롬프트로 설정된 시뮬라크럼이 경쟁적 또는 이기적 프롬프트에 비해 더 높은 협력 성향을 보임
- 반복 게임에서 더 높은 협력 수준이 나타났으며, 이는 일회성 게임과 대조적.
- 이타적 행동에 대한 증거는 혼합된 결과를 보였으며, 최신 모델은 협력적 성향이 강했으나, 초기 모델에서는 그런 경향성이 적음
- 통제 그룹은 협력적 시뮬라크럼과 매우 유사한 행동을 보여 조건부 상호성이 GPT 모델의 기본 행동 패턴일 수 있음을 시사합니다.
- GPT 모델이 독재자 게임(DG)에서 보인 전반적인 관대함은 인간 실험 결과와 대체로 유사
- 그러나 여러 변수들이 기부 수준을 변경할 수 있어, 인간과 기계의 비교는 복잡한것을 확인
- **죄수의 딜레마(PD)**에서는 인간 실험과 비슷한 수준의 협력 확률을 보였으나, 인간은 전략적 고려가 더 중요한 역할
- GPT 모델의 "성격"은 단순히 프롬프트에 의해 결정되므로, 실제 인간의 성격과 비교하는 것은 어려움
- GPT 모델은 텍스트 기반 지식에 의존하며, 실제 경험이 없습니다. 이는 인간과 인공지능 사이의 본질적인 차이점을 보여줌
- 미래의 AI 발전은 GPT와 같은 모델을 인간의 협력 문제 해결에 더 효율적으로 사용할 수 있도록 할 수 있으며, 이를 위해서는 인간과 AI 간의 차이를 보다 깊이 이해하는 연구가 필요
- 독재자 게임(Dictator Game):
'논문 리뷰' 카테고리의 다른 글
| 멀티에이전트를 기반으로한 대용량언어모델 (5) | 2024.10.21 |
|---|---|
| ai는 경제적 행위자인가? 효용효과를 통해 바라보는 llms의 행동적 편견 (9) | 2024.10.21 |
| LLM 기반 멀티 에이전트 강화학습 : 현황과 미래 방향 (0) | 2024.10.20 |
| 시장은 그 스스로 비정상성을 제거하는가? -논문 리뷰 (2) | 2024.10.20 |
| zero-intelligence robots and the double auction market: a graphical tour( 제로 지능 로봇과 이중 경매 시장 (4) | 2024.10.13 |